Khóa Học Data Science & Machine Learning Advance 2026


Thời lượng
52 buổi

Hình thức đào tạo
Online qua Zoom/MS Teams

Học phí
Liên hệ
Tổng quan
Bạn muốn chuyển mình sang ngành IT hoặc bứt phá thu nhập với dữ liệu? Khóa học Data Science & Machine Learning Advance 2026 tại Cole giúp bạn đi từ con số 0 đến tự tay triển khai hệ thống AI/ML chuẩn doanh nghiệp chỉ sau 52 buổi.
Ngành Khoa học dữ liệu (Data Science) đang là "trái tim" của kỷ nguyên chuyển đổi số và tăng trưởng bền vững tại Việt Nam. Nhu cầu tuyển dụng các vị trí khát nhân lực như Data Analyst, Data Scientist, BI Analyst, Machine Learning Engineer hay Data Engineer ngày càng bùng nổ. Đặc biệt, các lĩnh vực tài chính, thương mại điện tử, sản xuất, y tế, logistics và ngân hàng đang ráo riết săn lùng nhân tài.
Cơ hội nghề nghiệp & Mức lương Data Scientist / ML Engineer năm 2026
Hiện nay, mức lương dành cho chuyên viên phân tích dữ liệu vô cùng hấp dẫn, dao động từ 14 đến 70 triệu đồng/tháng tùy thuộc vào kỹ năng và kinh nghiệm. Nhiều tập đoàn lớn như FPT, VinGroup, VNG, cùng các Startup công nghệ đang đầu tư hàng triệu đô vào dữ liệu để tạo ra lợi thế cạnh tranh cốt lõi trên thị trường.
Tại sao nên học Data Science & Machine Learning ngay lúc này?
Dù nhu cầu tuyển dụng khổng lồ, thị trường vẫn đang đối mặt với tình trạng thiếu hụt trầm trọng nguồn nhân lực chuyên môn sâu. Tham gia một khóa học Data Science toàn diện chính là bước đi chiến lược. Khác biệt với các khóa lý thuyết trên thị trường, Cole mang đến lợi thế cạnh tranh độc quyền (USPs) cho bạn:
- Thực chiến 60% thời lượng: Làm việc trực tiếp trên tập dữ liệu và bài toán doanh nghiệp thật.
- Bao trọn kỹ năng MLOps: Không chỉ dừng ở phân tích, bạn sẽ được học cách đưa mô hình AI lên hệ thống Cloud (Docker, Airflow, CI/CD) – kỹ năng được nhà tuyển dụng săn đón nhất hiện nay.
- Cam kết đầu ra: Cole hỗ trợ giới thiệu việc làm, kết nối học viên với mạng lưới hơn 300 đối tác doanh nghiệp hàng đầu.
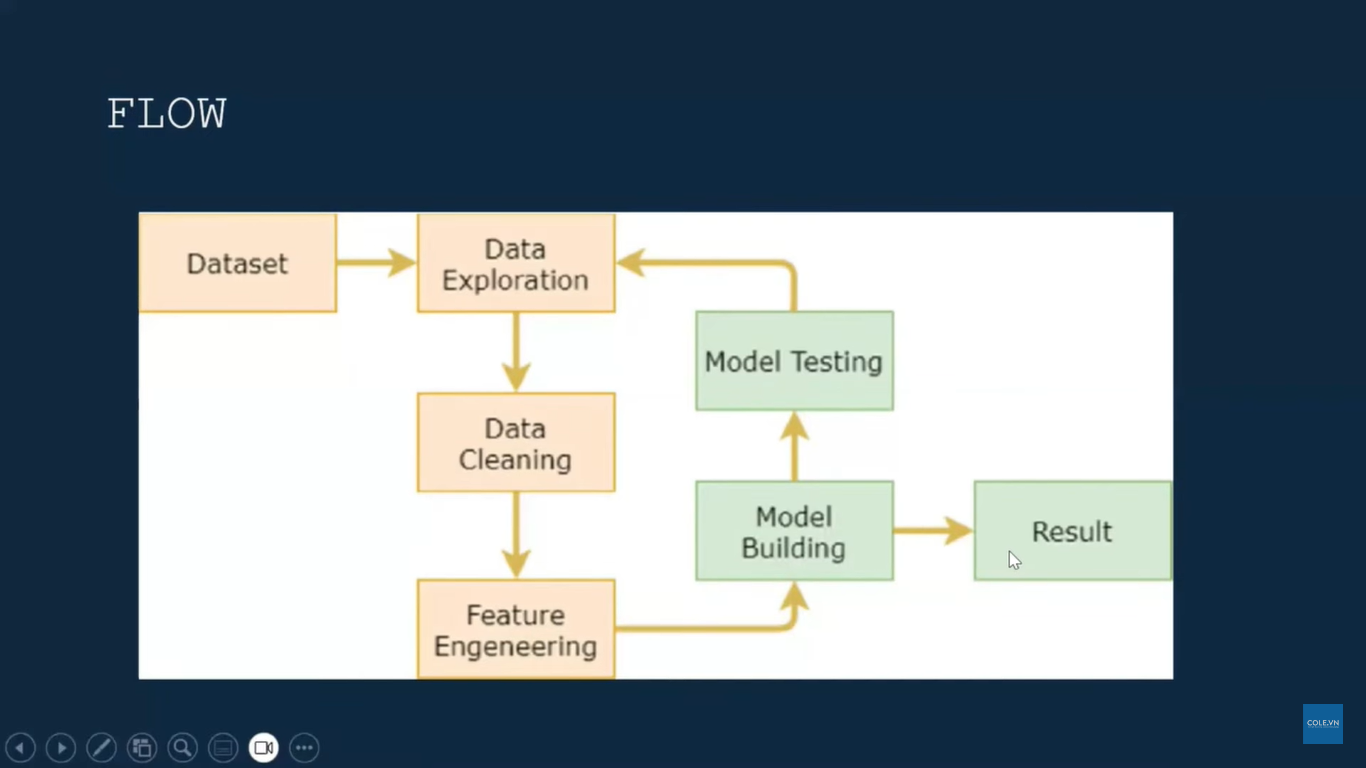
Lộ Trình Đào Tạo Data Science & Machine Learning Advance 2026
Chương trình được thiết kế theo lộ trình Hệ thống – Toàn diện – Thực tiễn, giúp bạn bứt phá năng lực:
- Xây nền tảng vững chắc: Làm chủ cơ sở dữ liệu SQL, Power BI và phân tích dữ liệu với ngôn ngữ Python từ cơ bản đến nâng cao.
- Chinh phục AI/ML: Áp dụng Machine Learning, Deep Learning (Hồi quy, Phân lớp, Hệ gợi ý) để giải quyết triệt để các bài toán thực tế.
- Lộ trình thăng tiến rõ ràng: Định hướng phát triển từ một Data Analyst vững tay nghề tiến thẳng lên các vai trò cấp cao như Data Scientist và Machine Learning Engineer.

Cạnh tranh bằng Data bao gồm:
Lợi ích khóa học
Đào tạo trực tuyến
Các buổi học sẽ diễn ra qua các nền tảng trực tuyến như Zoom, Microsoft Teams. Học viên tham gia các buổi học trực tiếp với giảng viên qua hình thức online.
Lý thuyết và thực hành
60% lý thuyết và 40% thực hành. Các bài thực hành được lấy từ các bài toán thực tế, giúp học viên áp dụng ngay kiến thức vào công việc.
Tài liệu học tập
Slide bài giảng, hướng dẫn thực hành các dự án thực tế tại doanh nghiệp một cách chi tiết.
Video bài giảng
Học viên có thể xem lại video các buổi học để ôn tập và nắm vững kiến thức mọi lúc mọi nơi.
Tương tác trực tiếp
Học viên có thể trao đổi trực tiếp 1-1 với giảng viên hoặc trợ giảng để được giải đáp thắc mắc và hỗ trợ trong quá trình học.
Mục tiêu học tập
Đối tượng học tập
Chuẩn đầu ra
Biết
Biết
Kiến thức và kỹ năng cốt lõi:
- Nắm vững các kiến thức nền tảng về xác suất thống kê, đại số tuyến tính, giải tích.
- Hiểu rõ quy trình phân tích dữ liệu thăm dò (Exploratory Data Analysis – EDA).
- Biết sử dụng Python, SQL để xử lý, phân tích và trực quan hóa dữ liệu.
- Làm quen với các kỹ thuật học máy (Machine Learning) như Decision Tree, Random Forest, Gradient Boosting và Deep Learning cơ bản.
- Nhận thức về các loại hệ quản trị cơ sở dữ liệu như RDBMS, NoSQL, Graph Database, và dữ liệu lớn (ElasticSearch).


Hiểu
Hiểu
Năng lực phân tích và triển khai:
- Phân biệt cách áp dụng các thuật toán và công cụ xử lý dữ liệu phù hợp với từng bài toán thực tiễn.
- Hiểu tầm quan trọng của làm sạch và chuẩn hóa dữ liệu để đảm bảo chất lượng phân tích.
- Giải thích được cách đánh giá mô hình, áp dụng A/B Testing trong các dự án doanh nghiệp.
Áp dụng
Áp dụng
Cơ hội nghề nghiệp và ứng dụng thực tế:
- Có thể đảm nhiệm vai trò Junior Data Analyst hoặc Fresher Data Scientist.
- Thực hiện thu thập dữ liệu từ file, API, database; xử lý và phân tích theo quy trình chuyên nghiệp.
- Thiết kế dashboard trực quan bằng Power BI, Streamlit, Excel để trình bày kết quả phân tích.
- Tham gia phát triển POC cho các bài toán phân tích – dự báo trong doanh nghiệp.

Lộ trình học tập
- So sánh cơ sở dữ liệu quan hệ với phi quan hệ
- Hệ quản trị cơ sở dữ liệu (RDBMS)
- Cơ sở dữ liệu (DB)
- Ngôn ngữ SQL
- Chương trình giúp người dùng giao tiếp với cơ sở dữ liệu (MySQL Workbench)
- Thiết lập môi trường truy vấn Workbench
- Tạo cơ sở dữ liệu qua Copy and Paste
- Tạo cơ sở dữ liệu qua Import, Export
- Gõ các câu truy vấn SQL theo mẫu
- Đọc nội dung của một số câu truy vấn SQL
- Cấu trúc, ví dụ cụ thể cho từng câu lệnh
- Select
- Where và các điều kiện logic: AND, OR
- Các hàm cơ bản trong MySQL
- Các hàm tổng hợp dữ liệu trong MySQL: SUM(), COUNT()
- GROUP BY, ORDER BY, HAVING, LIMIT
- SELECT, SELECT DISTINCT, AS, ORDER BY, WHERE, LIMIT, GROUP BY, HAVING
- Nhóm toán tử logic
- AND, OR, IN, BETWEEN, NULL
- Nhóm hàm toán học
- SUM, COUNT
- Các bảng, view của một CSDL
- Các cột của một bảng và tính chất các cột
- Đọc Diagram
- Quan hệ dữ liệu: 1-1; 1-n; n-n
- Khóa: Primary Key; Foreign Key
- Kiểu dữ liệu
- Union: Khái niệm, ví dụ
- View: Các kiểu view
- Đọc và phân tích được cơ sở dữ liệu từ lược đồ quan hệ
- Truy vấn các bảng của cơ sở dữ liệu
- Delete: Xóa dòng, ý nghĩa mệnh đề WHERE
- Update: Cập nhật dữ liệu, ý nghĩa mệnh đề WHERE
- Table, View, các ràng buộc: Key (PK, UK)
- Tối ưu qua Index
- Procedure
- Join (LEFT JOIN, RIGHT JOIN, INNER JOIN), Union, View
- Tạo cấu trúc và thủ tục
- Table, View, Procedure
- Truy vấn từ cơ bản đến nâng cao để tìm hiểu cơ sở dữ liệu
- Xây dựng cơ sở dữ liệu OLAP
- Xây dựng dashboard trên OLTP (Excel hoặc Power BI)
- Xây dựng dashboard trên OLAP
- Chia sẻ các nội dung chuyên sâu
- Hỏi đáp thắc mắc
- Các bài toán phổ biến và quan trọng trong lĩnh vực Khoa học Dữ liệu
- Python trong Data Science
- Tổng quan kiến thức cơ bản về Machine Learning cần thiết trong khóa học
- Giới thiệu và hướng dẫn cài đặt môi trường thực hành như Jupyter Notebook, Colab, v.v.
- Biến và các kiểu dữ liệu
- Input & print trong Python
- Áp dụng các kiểu dữ liệu nào trong thực tế?
- Biểu thức điều kiện
- Vòng lặp For, While
- Tự động hóa các tác vụ lặp đi lặp lại
- Gọi hàm trong Python
- Biến cục bộ và biến toàn cục
- Hàm lambda
- Khởi tạo List
- Truy cập phần tử trong List (truy cập bằng index, truy cập đầu cuối danh sách)
- Thao tác trên List (thêm, xóa, thay đổi giá trị phần tử)
- Cắt (slicing) List
- Các phương thức List (sort(), reverse(), count(), index(), extend())
- Các thao tác trên Tuple
- Cú pháp tạo Tuple bằng dấu ngoặc tròn ()
- Truy cập phần tử trong Tuple
- Thao tác với Tuple
- Ứng dụng của Tuple
- Tuple packing và unpacking
- Khởi tạo và thao tác trên Dictionaries và Sets
- Ứng dụng của Dictionaries và Sets
- Phương thức
- Package và import
- Thực hành: lớp và đối tượng
- Đối tượng Groupby
- Làm việc với DataFrame
- Chèn, xóa, sửa dòng và cột trong DataFrame
- Sắp xếp dữ liệu trong DataFrame
- Các biểu đồ cơ bản
- Lợi ích của Seaborn
- Biểu đồ trong Seaborn
- Scalar, Vector, Matrix, Tensor: Cách máy tính "nhìn" dataset và hình ảnh
- Hàng (Sample) và Cột (Feature) trong không gian dữ liệu
- Độ đo & Khoảng cách
- Dot Product & Cosine Similarity: Đo độ tương đồng giữa các vector (ứng dụng trong NLP, Recommendation)
- Norms (L1, L2): Các cách đo khoảng cách và độ lớn của vector
- Ma trận & Biến đổi tuyến tính
- Phép nhân ma trận (Matrix Multiplication): Bản chất là phép biến đổi, quay và co giãn không gian (nền tảng của Neural Networks)
- Ma trận nghịch đảo & Định thức (Determinant)
- Phân rã ma trận (Dimensionality Reduction)
- Eigenvalues & Eigenvectors: Tìm ra "trục chính" chứa thông tin quan trọng nhất của dữ liệu
- PCA (Principal Component Analysis): Nguyên lý giảm chiều dữ liệu
- Phân biệt giữa thống kê mô tả và thống kê suy luận
- Sử dụng thống kê mô tả (Python) để
- Tóm tắt nhanh dữ liệu
- Đo lường trung tâm dữ liệu
- Đo lường độ phân tán dữ liệu
- Đo lường vị trí tương đối của dữ liệu
- Khám phá cách sử dụng định lý Bayes để mô tả các sự kiện phức tạp
- Học cách sử dụng các phân phối xác suất (nhị thức, Poisson, chuẩn) để hiểu rõ cấu trúc dữ liệu
- Tìm hiểu cách tránh sai lệch do chọn mẫu
- Học cách sử dụng phân phối mẫu để đưa ra ước lượng chính xác
- Sử dụng mẫu nhỏ để suy luận về tập dữ liệu lớn
- Học cách xây dựng và diễn giải khoảng tin cậy
- Tìm hiểu cách tránh các hiểu lầm phổ biến liên quan đến khoảng tin cậy
- Kiểm định giả thuyết giúp xác định tính ý nghĩa thống kê của kết quả so với ngẫu nhiên
- Học các bước cơ bản của một kiểm định giả thuyết
- Hiểu cách kiểm định giả thuyết giúp đưa ra kết luận có ý nghĩa về dữ liệu
- Áp dụng kiến thức thống kê để đánh giá thêm về dữ liệu và mô hình trực quan hóa
- Giới thiệu các thuật toán Hồi quy phổ biến như Linear Regression, Logistic Regression,...
- Cách tiếp cận và xây dựng một mô hình Hồi quy trong các tình huống thực tế
- Các phương pháp để đánh giá hiệu suất và độ chính xác của một hệ thống Hồi quy
- Setup môi trường Google Colab
- Thực hành chạy một số đoạn Python code, Markdown cơ bản
- Load và xử lý dữ liệu cơ bản với pandas
- Giới thiệu các thuật toán Phân loại phổ biến như Linear classifiers, Decision Tree, SVM,...
- Cách tiếp cận và xây dựng một mô hình phân loại trong các tình huống thực tế
- Các phương pháp để đánh giá hiệu suất và độ chính xác của một hệ thống phân loại
- Xây dựng các mô hình hồi quy bằng thư viện sklearn
- Đánh giá, so sánh độ chính xác của các mô hình hồi quy
- Tự thực hành
- Học viên tự áp dụng các kiến thức đã được hướng dẫn trên các bộ dữ liệu khác
- Học viên tự điều tra và thử nghiệm nhiều mô hình khác nhau và đưa ra đánh giá
- Cung cấp cơ hội cho học viên đặt câu hỏi và nhận được sự giải đáp từ giảng viên hoặc các thành viên khác trong khóa học
- Tổng quan về bài tập lớn (Project) của khóa học, đưa ra mục tiêu, yêu cầu và quá trình thực hiện của dự án
- Xử lý dữ liệu, trích rút đặc trưng văn bản
- Xử lý bài toán phân loại sắc thái bình luận
- Tự thực hành
- Học viên tự áp dụng các kiến thức đã được hướng dẫn trên các bộ dữ liệu khác
- Học viên tự điều tra và thử nghiệm nhiều mô hình khác nhau và đưa ra đánh giá
- Giới thiệu về khái niệm độ tương đồng trong phân cụm, là một phép đo để đánh giá sự tương đồng giữa các điểm dữ liệu
- Giới thiệu một số phương pháp mã hóa văn bản như Bag-of-Words, TF-IDF và Word Embedding để biểu diễn văn bản thành dữ liệu số hóa
- Hướng dẫn thực hành giải quyết bài toán truy xuất và phân cụm tài liệu, sử dụng các kỹ thuật và công cụ như K-Means và phương pháp mã hóa văn bản để xử lý và phân tích các tài liệu dựa trên nội dung của chúng
- Phân tích cách tiếp cận một bài toán hồi quy, phân loại khi gặp một bộ dữ liệu mới
- Tổng hợp các kiến thức học viên tự tìm hiểu ở 2 buổi trước
- Phân tích ưu nhược điểm của các phương pháp xử lý dữ liệu và các mô hình khác nhau
- Tổng quan về một số thuật toán phổ biến trong hệ thống gợi ý như Lọc cộng tác, Gợi ý dựa trên nội dung,...
- Cách tiếp cận và quy trình xây dựng một hệ thống gợi ý trong môi trường thực tế, từ việc thu thập dữ liệu đến xây dựng mô hình và triển khai
- Giới thiệu các phương pháp để đánh giá hiệu suất và độ chính xác của một hệ thống gợi ý
- Hướng dẫn thực hành xây dựng và đánh giá hệ thống gợi ý trên một bộ dữ liệu thực tế, áp dụng các thuật toán và phương pháp đã học vào thực tế
- Tìm hiểu phương pháp đánh giá độ tương đồng văn bản
- Xây dựng mô hình phân cụm K-Means phân cụm văn bản
- Đánh giá kết quả mô hình
- Tự thực hành
- Học viên tự áp dụng các kiến thức đã được hướng dẫn trên các bộ dữ liệu khác
- Học viên tự điều tra và thử nghiệm nhiều mô hình khác nhau và đưa ra đánh giá
- Các phương pháp và định dạng để biểu diễn luật kết hợp, bao gồm dạng tập hợp, dạng chuỗi và dạng cây
- Phương pháp khai thác và tìm kiếm các mẫu phổ biến từ dữ liệu như tìm tập hợp phổ biến, chuỗi phổ biến hoặc cây phổ biến
- Khám phá các luật kết hợp từ các mẫu phổ biến
- Phân tích tương quan giữa các mẫu hoặc thuộc tính dữ liệu để tìm hiểu sự tương quan và tương tác giữa chúng, đồng thời đưa ra các phân tích và nhận định về mối quan hệ
- Xử lý dữ liệu cho bài toán hệ gợi ý
- Xây dựng mô hình lọc cộng tác cho bài toán gợi ý phim
- Đánh giá kết quả gợi ý của mô hình
- Tự thực hành
- Học viên thử nghiệm phương pháp gợi ý dựa trên nội dung
- Cung cấp cơ hội cho học viên đặt câu hỏi và nhận được sự giải đáp từ giảng viên hoặc các thành viên khác trong khóa học
- Học viên sẽ được giới thiệu tổng quan về bài tập lớn (Project) của khóa học, bao gồm mục tiêu, yêu cầu và quy trình thực hiện của dự án
- Xử lý dữ liệu cho bài toán khai phá luật kết hợp
- Xây dựng mô hình luật kết hợp cho bài toán giỏ hàng
- Đánh giá kết quả của mô hình
- Tự thực hành
- Học viên thử nghiệm phương pháp khai phá luật kết hợp
- Giới thiệu về xử lý và phân tích hình ảnh thông qua công nghệ thị giác máy tính và các ứng dụng trong thực tế
- Giới thiệu về xử lý ngôn ngữ tự nhiên và các phương pháp, công cụ để xử lý, phân tích và hiểu văn bản tự nhiên
- Phân tích cách tiếp cận một bài toán hồi quy, phân loại khi gặp một bộ dữ liệu mới
- Tổng hợp các kiến thức học viên tự tìm hiểu ở 3 buổi trước
- Phân tích ưu nhược điểm của các phương pháp xử lý dữ liệu và các mô hình khác nhau
- Hàm mất mát và điều chỉnh trọng số
- Thuật toán Gradient Descent
- Thuật toán Stochastic Gradient Descent
- Thuật toán Mini-batch Gradient Descent
- Thực hiện các thay đổi thông số khác nhau trên mô hình hồi quy hoặc phân lớp dùng ANN đã xây dựng từ buổi trước để hiểu rõ hơn về Gradient Descent và Loss
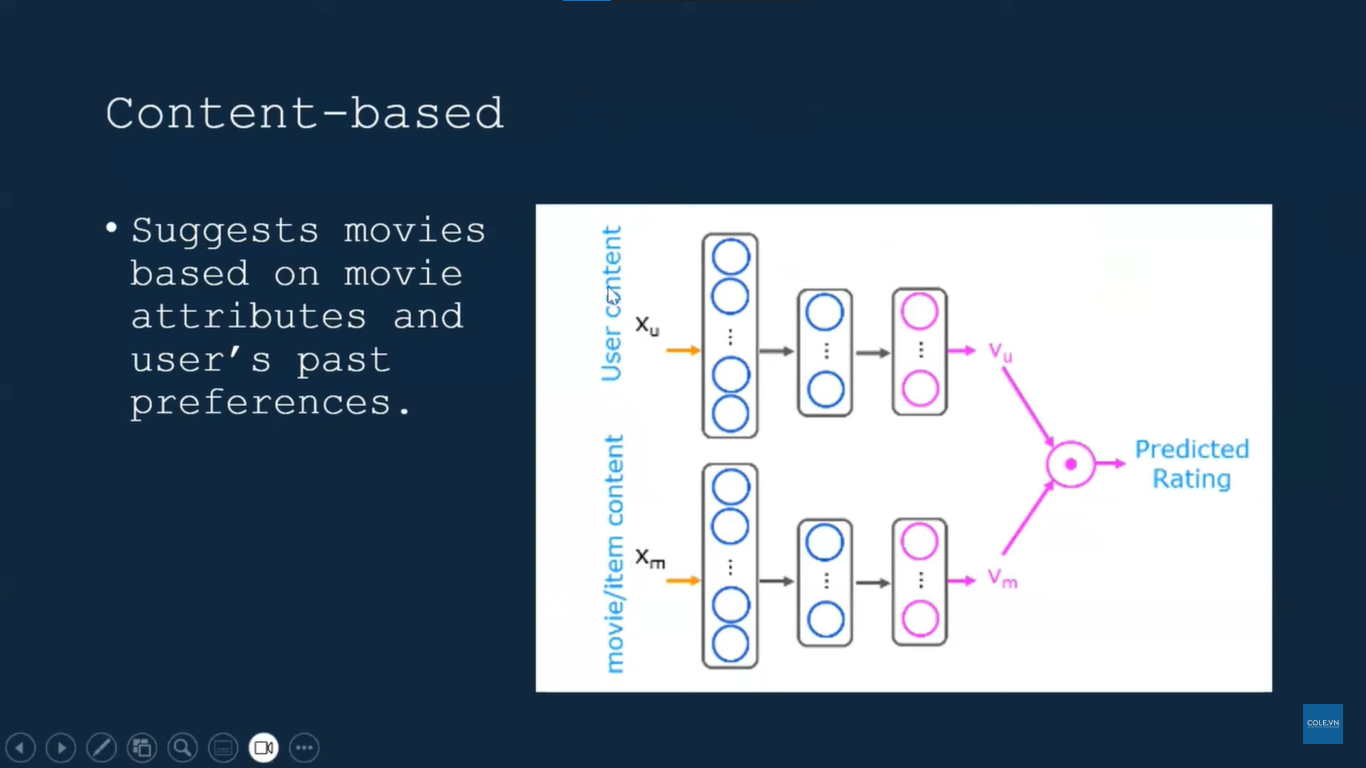
- Hệ thống gợi ý lai (Hybrid Systems): Kỹ thuật kết hợp giữa Content-based và Collaborative Filtering để khắc phục nhược điểm của từng loại (ví dụ: mô hình Wide & Deep của Google)
- Word/Item Embeddings: Ứng dụng Word2Vec hoặc Item2Vec để biểu diễn sản phẩm dưới dạng vector, giúp tìm kiếm sự tương đồng chính xác hơn
- Gợi ý theo phiên (Session-based Recommendation): Sử dụng RNN hoặc LSTM để dự đoán hành vi người dùng dựa trên chuỗi hành động ngắn hạn (ví dụ: vừa xem giày, vừa xem tất → gợi ý dây giày) thay vì lịch sử dài hạn
- Xây dựng Item2Vec (Embeddings)
- Xây dựng mô hình Neural Collaborative Filtering (NCF) - Trọng tâm
- Demo hệ thống gợi ý theo phiên (Session-based RecSys) với RNN/LSTM
- Xây dựng mô hình học sâu và các thành phần cơ bản
- Học cách huấn luyện một mô hình học sâu
- Tổng kết Module 4 về lý thuyết
- Hỏi đáp về Mini-Project
- Các đặc trưng cốt lõi: Trend (Xu hướng), Seasonality (Mùa vụ), Cyclical (Chu kỳ), Noise (Nhiễu)
- Khái niệm Stationarity (Tính dừng): Tại sao chuỗi thời gian cần phải "dừng" để dự báo? Kiểm định Dickey-Fuller (ADF test)
- Thư viện Pandas: pd.to_datetime, set index là ngày tháng
- Resampling (gom nhóm dữ liệu): Chuyển dữ liệu theo giờ thành ngày/tháng (.resample())
- Xử lý dữ liệu thiếu (Missing values): Forward fill, Backward fill, Interpolation
- Vẽ biểu đồ cơ bản để nhìn ra Trend/Seasonality
- Tự tương quan (ACF) và Tự tương quan riêng phần (PACF): Công cụ để tìm quy luật trễ (lags)
- Các kỹ thuật làm mịn: Simple Moving Average (SMA), Exponential Smoothing (ETS), Holt-Winters
- Sử dụng seasonal_decompose để tách Trend, Seasonality, Residual
- Vẽ và đọc biểu đồ ACF/PACF (bước đệm quan trọng cho ARIMA)
- Thực hành làm mượt dữ liệu chứng khoán hoặc doanh số bán hàng để thấy xu hướng rõ hơn
- ARIMA (p, d, q): Ý nghĩa từng tham số và cách chọn dựa trên ACF/PACF
- SARIMA: Mở rộng cho dữ liệu có tính mùa vụ (ví dụ: doanh số tăng vào cuối tuần)
- Sử dụng thư viện statsmodels
- Quy trình chuẩn: Kiểm tra tính dừng → Sai phân → Tìm p, q → Fit mô hình
- Auto-ARIMA (thư viện pmdarima): Tự động tìm tham số tối ưu (cách làm thực tế)
- Phân tích phần dư (Residual analysis): Kiểm tra độ tin cậy của mô hình
- Giới thiệu Facebook Prophet: Dễ dùng, xử lý tốt outliers và dữ liệu thiếu
- Tư duy Supervised Learning cho Time Series: Phương pháp Sliding Window (Cửa sổ trượt) - Bước chuẩn bị quan trọng để hiểu Input của LSTM ở buổi sau
- Cài đặt và chạy Prophet: Thêm holidays (ngày lễ) vào mô hình dự báo
- Feature Engineering: Tạo các cột lag_1, lag_7, rolling_mean
- Thử nghiệm chạy Random Forest hoặc XGBoost để thấy sự khác biệt với ARIMA
- Metrics đánh giá: MAE, RMSE, MAPE (Khi nào dùng cái nào?)
- Backtesting: Tại sao train_test_split ngẫu nhiên là sai lầm trong Time Series? Giới thiệu TimeSeriesSplit
- Giới thiệu Deep Learning cho chuỗi thời gian
- RNN (Recurrent Neural Networks): Tại sao cần "bộ nhớ" (Memory) thay vì chỉ học độc lập như Regression?
- Vấn đề của RNN: "Trí nhớ ngắn hạn" (Vanishing Gradient)
- LSTM (Long Short-Term Memory) & GRU: Giải thích nôm na về cơ chế "Cổng" (Gate) giúp mô hình nhớ được quy luật dài hạn và quên đi nhiễu
- Demo LSTM
- Chạy một mô hình LSTM đơn giản bằng thư viện Keras/TensorFlow trên cùng bộ dữ liệu của Buổi 3/4
- Cho học viên thấy sự khác biệt về cách chuẩn bị dữ liệu (Data Scaling về [0,1] là bắt buộc với LSTM, trong khi ARIMA thì không cần)
- Hướng dẫn về việc xác định và thu thập dữ liệu phù hợp cho bài toán, bao gồm các nguồn dữ liệu, phương pháp thu thập và quy trình xử lý dữ liệu
- Hướng dẫn về quy trình khai phá dữ liệu (EDA) để hiểu cấu trúc và tính chất của dữ liệu. Bên cạnh đó, cung cấp hướng dẫn về các phương pháp biểu diễn trực quan dữ liệu như biểu đồ, đồ thị hoặc bản đồ để hỗ trợ quá trình khai phá và hiểu rõ hơn về dữ liệu
- Sử dụng thư viện pandas, matplotlib để khai phá dữ liệu và biểu diễn trực quan dữ liệu đầu vào, đầu ra
- Thực hành các hàm biểu diễn dữ liệu có trong thư viện
- Tự thực hành
- Học viên thử nghiệm với các bộ dữ liệu khác nhau
- Hướng dẫn về cách khai thác thông tin từ các trường dữ liệu có sẵn và tạo ra các trường dữ liệu mới dựa trên kiến thức và hiểu biết về bài toán. Điều này có thể bao gồm việc kết hợp, biến đổi hoặc áp dụng các quy tắc và hàm tính toán để tạo ra thông tin mới từ dữ liệu hiện có
- Hướng dẫn về việc mã hóa và chuẩn hóa dữ liệu để đảm bảo tính nhất quán và khả năng so sánh giữa các đặc trưng. Bao gồm các phương pháp như mã hóa one-hot, mã hóa số hóa, chuẩn hóa z-score và chuẩn hóa min-max để biến đổi và điều chỉnh các giá trị dữ liệu thành dạng phù hợp và thống nhất
- Sử dụng thư viện pandas, numpy thực hiện các phương pháp mã hóa dữ liệu như Label Encoder, One-Hot Encoder,...
- Thực hành các phương pháp chuẩn hóa dữ liệu
- Tự thực hành
- Học viên thử nghiệm với các bộ dữ liệu khác nhau
- Hướng dẫn về quá trình xây dựng mô hình, bao gồm việc định nghĩa kiến trúc mô hình, khởi tạo các tham số và quyết định các thông số quan trọng như learning rate, số lượng layer, kích thước batch, v.v.
- Hướng dẫn về quá trình huấn luyện mô hình base, bao gồm việc chuẩn bị dữ liệu huấn luyện, chia thành batch, tạo bộ kiểm tra, lựa chọn hàm mất mát và phương pháp tối ưu hóa, đánh giá và tinh chỉnh mô hình dựa trên kết quả huấn luyện
- Xây dựng các mô hình phù hợp cho bài toán
- Huấn luyện mô hình bằng thư viện sklearn
- Hướng dẫn về cách tối ưu các tham số của mô hình trong quá trình huấn luyện. Điều này có thể bao gồm việc sử dụng phương pháp tìm kiếm lưới (Grid Search) để thử nghiệm các giá trị khác nhau cho các tham số, sử dụng kỹ thuật tinh chỉnh tự động (Automated Tuning) như tối ưu Bayes (Bayesian Optimization), hoặc sử dụng phương pháp tinh chỉnh thông qua việc giảm thiểu hàm mất mát (Loss Function Minimization)
- Thay đổi tham số, thử nghiệm tối ưu các tham số
- Huấn luyện mô hình với các bộ tham số khác nhau
- Sử dụng GridSearch để tìm ra bộ tham số tốt nhất
- Đánh giá mô hình và lựa chọn mô hình tốt nhất: Sử dụng các phương pháp như cross-validation, độ đo hiệu suất và so sánh mô hình để lựa chọn mô hình tốt nhất cho áp dụng thực tế
- Phân tích kết quả huấn luyện các mô hình đã huấn luyện ở các buổi trước, đưa ra phán đoán nhằm cải thiện chất lượng
- Xây dựng một quy trình tự động hoàn chỉnh để xử lý dữ liệu, huấn luyện mô hình và triển khai mô hình trong môi trường thực tế. Quy trình này bao gồm các bước từ chuẩn bị dữ liệu, tiền xử lý, huấn luyện mô hình, đánh giá, triển khai và cập nhật mô hình
- Sử dụng thư viện FastAPI để xây dựng API, triển khai mô hình
- Sử dụng MLflow để xây dựng pipeline cho toàn bộ quá trình
- Sử dụng Streamlit để xây dựng web POC cho mô hình
- Tự thực hành
- Học viên thử nghiệm với các loại mô hình khác nhau
- Các hướng giải quyết khác có thể áp dụng để đạt được kết quả tốt hơn, khám phá và nghiên cứu thêm về các phương pháp mới và tiến bộ trong lĩnh vực khoa học dữ liệu
- Một số vấn đề cần chú ý khi áp dụng vào hệ thống dữ liệu lớn trong thực tiễn doanh nghiệp bao gồm quy mô, tính khả thi, hiệu suất, bảo mật và tính ổn định của hệ thống và các yếu tố khác như quản lý dữ liệu, quản lý tài nguyên và tương tác với các thành phần khác trong hệ thống
- Học viên đặt câu hỏi, chia sẻ kinh nghiệm và thảo luận về project
- Đánh giá tiến độ và kết quả học tập: Xem xét và đánh giá tiến bộ cá nhân và kết quả học tập của mỗi học viên để đảm bảo họ đã đáp ứng được các mục tiêu và yêu cầu của khóa học
- Thảo luận về ứng dụng thực tế: Trao đổi về cách áp dụng kiến thức đã học vào thực tế và giải quyết các vấn đề trong lĩnh vực tương ứng
- Phân tích và đánh giá project: Đánh giá và phân tích kết quả của các dự án đã thực hiện bởi các nhóm học viên, bao gồm sự đóng góp, hiệu suất và tính khả thi của các giải pháp
- Tổng kết và phản hồi: Tổng kết khóa học bằng cách cung cấp phản hồi về nội dung, phương pháp giảng dạy và trải nghiệm học tập nhằm cải thiện chất lượng của khóa học trong tương lai
- Khái niệm hyperparameter và sự khác biệt giữa hyperparameter và model parameter; ảnh hưởng của chúng đến độ chính xác và khả năng tổng quát của mô hình
- Các phương pháp tinh chỉnh siêu tham số: Grid Search, Random Search, Bayesian Optimization; khi nào nên dùng mỗi phương pháp
- Quản lý version của mô hình và thí nghiệm: tại sao việc theo dõi lịch sử huấn luyện là bắt buộc trong môi trường thực tế
- Kết quả
- Các thử nghiệm huấn luyện được ghi lại có hệ thống, dễ so sánh và truy xuất
- Xác định và đăng ký được mô hình tốt nhất dựa trên metric đã chọn
- Học viên hiểu và áp dụng được quy trình quản lý vòng đời mô hình (Model Lifecycle)
Thực hành:
- Áp dụng các kỹ thuật tinh chỉnh hyperparameter cho một mô hình ML cụ thể (ví dụ: Random Forest hoặc XGBoost)
- Sử dụng MLflow để log hyperparameters, metrics, artifacts (model, confusion matrix, file kết quả)
- Đăng ký (register) nhiều phiên bản mô hình và so sánh hiệu suất giữa các lần thử nghiệm
- Vì sao không nên huấn luyện mô hình thủ công và vai trò của workflow orchestration trong ML
- Cách chuyển Jupyter Notebook sang Python Script theo chuẩn production
- Giới thiệu Airflow, DAG, Task, Operator và các best practices khi thiết kế pipeline
- Kết quả
- Một pipeline tự động huấn luyện mô hình theo lịch (ví dụ: chạy hàng ngày)
- Quy trình huấn luyện ổn định, có thể mở rộng và dễ bảo trì
- Học viên hiểu cách tích hợp ML vào hệ thống vận hành thực tế
Thực hành:
- Refactor notebook huấn luyện mô hình thành Python script có thể tái sử dụng
- Xây dựng một Airflow DAG gồm các bước: load data → train model → evaluate → lưu model
- Chạy và theo dõi pipeline huấn luyện mô hình trực tiếp trên Airflow UI
- Khái niệm Model Serving và vai trò của API trong hệ thống ML/AI
- Cách tổ chức Python project cho inference (load model, preprocess, predict)
- Giới thiệu FastAPI, request/response schema và các nguyên tắc thiết kế API cho ML
- Kết quả
- Một API web cục bộ có thể phục vụ dự đoán từ mô hình đã huấn luyện
- Mô hình sẵn sàng để tích hợp vào các hệ thống khác (web, mobile, backend)
- Học viên hiểu quy trình triển khai inference chuẩn production
- Chuyển notebook inference thành Python module rõ ràng, tách biệt logic
- Xây dựng FastAPI server để load mô hình và nhận input dự đoán
- Gửi request từ client (curl/Postman/Python) và nhận kết quả dự đoán
- Cách viết test đảm bảo API hoạt động đúng như mong muốn
- Docker là gì và vì sao Docker là tiêu chuẩn trong triển khai ML
- Cấu trúc của Docker image, Dockerfile và container lifecycle
- Khái niệm portability: “build một lần – chạy ở mọi nơi”
- Kết quả
- Một Docker container độc lập, có thể chạy ML service mà không phụ thuộc môi trường
- Service ML dễ dàng chia sẻ, triển khai và mở rộng
- Học viên nắm được kỹ năng đóng gói ML application theo chuẩn công nghiệp
Thực hành:
- Viết Dockerfile cho FastAPI service đã xây dựng ở buổi trước
- Build Docker image và chạy container trên môi trường local
- Kiểm tra API hoạt động bình thường khi chạy trong container
- Sự khác biệt giữa code versioning trong ML và trong software truyền thống
- Khái niệm reproducibility và mối quan hệ giữa code, data và model
- Git workflow phổ biến cho dự án Machine Learning
- Vai trò của CI/CD trong việc đảm bảo chất lượng hệ thống ML
- Kết quả
- Repository ML có cấu trúc rõ ràng và sẵn sàng cho production
- CI pipeline tự động kiểm tra chất lượng code và inference service
Thực hành:
- Tự động chạy test trên Github
- Tự động build docker image bằng Github
- Tự động public image đã built lên Dockerhub sau khi được review và merge
- Cloud deployment là gì và sự khác biệt giữa local, on-premise và cloud
- Tổng quan các cloud services phổ biến (VM, container service, managed services)
- Các khái niệm cơ bản: public endpoint, security group, environment variable
- Kết quả
- Mô hình ML được triển khai thành công trên cloud
- API có thể truy cập từ bất kỳ đâu qua internet
- Học viên hoàn thành vòng đời triển khai ML từ local - cloud
Thực hành:
- Chọn một nền tảng cloud và triển khai Docker image của ML service
- Cấu hình port, environment variables và expose API ra internet
- Kiểm tra và gọi API thông qua URL công khai
- Tại sao cần giám sát mô hình sau khi triển khai (data drift, model degradation)
- Các loại metrics trong production: latency, error rate, prediction distribution
- Logging và monitoring khác gì so với evaluation trong quá trình huấn luyện
- Kết quả
- API được nâng cấp để ghi lại dự đoán và hành vi người dùng
- Dashboard hiển thị các chỉ số hiệu suất theo thời gian
- Học viên hiểu cách vận hành và giám sát mô hình ML trong môi trường production
Thực hành:
- Tích hợp loguru để ghi log request, response và kết quả dự đoán
- Thu thập metrics và hiển thị bằng Grafana, EvidentlyAI
- Phân tích log và metrics để phát hiện dấu hiệu suy giảm chất lượng mô hình
- Tổng quan vòng đời MLOps và vai trò của từng nhóm công cụ
- Quản lý phiên bản dữ liệu và mô hình với DVC
- Giới thiệu Kubeflow và các thành phần chính trong ML platform trên Kubernetes
- Khái niệm AutoML và managed ML services trên cloud
- Kết quả
- Học viên hiểu vai trò và phạm vi áp dụng của các công cụ MLOps phổ biến
- Học viên hình thành tư duy lựa chọn nền tảng MLOps phù hợp với quy mô và yêu cầu hệ thống
Thực hành:
- Minh hoạ workflow quản lý dữ liệu và mô hình với DVC
- Phân tích kiến trúc một pipeline ML sử dụng Kubeflow
- So sánh use case giữa tự xây dựng pipeline và sử dụng AutoML
- Thảo luận lựa chọn công cụ MLOps theo từng bối cảnh doanh nghiệp
Giảng viên

Giảng viên Khoa học máy tính - ĐH Ngoại Thương TP.HCM
Học vấn & chuyên môn:
• Tiến sĩ Khoa học Tính toán, chuyên sâu trong các lĩnh vực Mô phỏng số, Khoa học dữ liệu và Ứng dụng kỹ thuật.
Kinh nghiệm giảng dạy & công tác:
• Giảng viên Đại học Ngoại Thương TP. Hồ Chí Minh – giảng dạy Toán ứng dụng và Khoa học máy tính (3+ năm).
• Giảng viên Đại học Bách khoa TP. Hồ Chí Minh – Khoa Kỹ thuật Hàng không Vũ trụ và Giao thông Vận tải (3+ năm).
• Nghiên cứu viên tại Viện Năng lượng Ứng dụng – NUPEC (Nuclear Power Engineering Center), Tokyo, Nhật Bản (4+ năm).
• Kỹ sư CNTT tại DFM-Engineering (5+ năm).
• Hơn 10 năm nghiên cứu trong lĩnh vực Khoa học tính toán và Phân tích dữ liệu.
Thành tựu & đóng góp:
• Tham gia nhiều dự án nghiên cứu ứng dụng mô phỏng tính toán và phân tích dữ liệu năng lượng tại Nhật Bản.
• Giảng dạy, hướng dẫn nhiều khóa học chuyên sâu về Khoa học dữ liệu, mô hình hóa tính toán và các phương pháp tính toán kỹ thuật.

Giảng viên trường Đại học Bách khoa Hà Nội chuyên nghành Toán tin ứng dụng
- 10+ năm kinh nghiệm quản lý nhân sự 500+ người, sản phẩm 100K+ người dùng.
- Xây dựng Data Warehouse cho sản phẩm Topica Native 17+ năm.
- Giảng viên Viện Toán ứng dụng, Đại học Bách Khoa Hà Nội.
- 6+ năm kinh nghiệm đào tạo nhân sự quản lý cấp trung.
- Xây dựng chương trình Data Analyst và đào tạo trực tiếp cho 1000+ nhân sự.
- 15+ năm kinh nghiệm làm việc thực tế về Quản lý doanh nghiệp, xây dựng hệ thống phần mềm CNTT trên các công cụ lập trình cũng như Tin học văn phòng Excel, GoogleSheet, PowerBI.
- Đã đào tạo trực tiếp các phần mềm phân tích và xử lý dữ liệu trên Excel, GoogleSheet, PowerBI +2000 người.
- Đã đào tạo Online và Offline PowerBI cho hơn 100 nghìn người.
- Đào tạo/Coaching/Tư vấn cho nhiều bạn quản lý, chủ doanh nghiệp về một số mảng (xây dựng hệ thống, chiến lược marketing, xây dựng sản phẩm, tài chính, problem solving,...)
.png)
Chuyên gia Trí tuệ nhân tạo, Học máy & Hệ thống tính toán hiệu năng cao
Học vấn
- Cử nhân CNTT – Đại học Bách Khoa Hà Nội (2002)
- Thạc sĩ CNTT – Viện Tin học Pháp ngữ (IFI) (2005)
- Tiến sĩ CNTT – Đại học Blaise Pascal, Pháp (2012)
Kinh nghiệm giảng dạy & công tác
- Giảng viên Đại học Bách Khoa Hà Nội.
- Trưởng khoa CNTT – Đại học Greenwich Việt Nam (liên kết Đại học FPT & Đại học Greenwich UK).
- Hơn 20 năm kinh nghiệm giảng dạy, nghiên cứu và quản lý học thuật trong lĩnh vực CNTT.
- Chuyên môn: Trí tuệ nhân tạo (AI), Machine Learning, Công nghệ phần mềm, Hệ thống phân tán và Cấu trúc dữ liệu.
Hoạt động nghiên cứu & dự án khoa học
- Thành viên nhóm nghiên cứu VNGrid (2010).
- Đề tài hợp tác quốc tế về nghiên cứu hệ thống tính toán hiệu năng cao và mô phỏng vật liệu vi mô (2009).
- Hợp tác nghiên cứu và chuyển giao công nghệ với Centre for Development of Advanced Computing (Ấn Độ) (2014).
- Tham gia dự án EuAsiaGrid – xây dựng cổng thông tin gINFO Portal (2011).
- Đề tài nghiên cứu dịch vụ tin sinh trên nền điện toán đám mây cho các bài toán siêu bộ gen (2015–2016).
Thành tựu & công bố
- Công bố nhiều bài báo khoa học quốc tế về học sâu, hệ thống thông minh, nhận diện hình ảnh và xử lý thông tin.
- Các ứng dụng tiêu biểu: nhận diện thẻ căn cước, nhận dạng biển báo giao thông và hệ thống học máy phân tích dữ liệu lớn.
Dự án học viên
Feedback học viên

Vũ Minh Nhật
Data Scientist tại VP Bank

Mai Thị Hòa
Data Analyst tại Viettel

Đỗ Tiến Đạt
Data Scientist tại CMC
Lợi ích chỉ có tại COLE
Giới thiệu việc làm sau khóa học
Học lại free
Cộng đồng chuyển đổi số 1
Câu hỏi thường gặp
Để biết thêm thông tin chi tiết đừng ngần ngại gọi cho chúng tôi.
-
Hotline
-
Email
-
Trang tin chính thức
Hoặc để lại thông tin

COLE - Lựa chọn hàng đầu cho nhân
sự về Digital Skills

5000+
Học viên theo học

30%
Thu nhập học viên tăng lên sau khi học

30+ Khóa học
Hàng đầu về ứng dụng công nghệ

50+
Chuyên gia hàng đầu về chuyển đổi số
300+ Doanh nghiệp hàng đầu lựa chọn Cole để nâng cấp kỹ năng
Hình ảnh lớp học